
Mastodon was scraped, again. It was not the first time it had happened, and it probably wont be the last. This time it was for research, not just archiving which we had encountered in the past. The actual scraping happened in 2018, but the research was recently published, and this is why we’re talking about it now.
Background:
The research article, “Mastodon Content Warnings: Inappropriate Contents in a Microblogging Platform”, was written by authors from the Computer Science Department, University of Milan. The same group of people have previously published another research article related to Mastodon, “The Footprints of a “Mastodon”: How a Decentralized Architecture Influences Online Social Relationships”. In their previous paper they also had a lot of misunderstandings of the technology as well as the culture of Mastodon.
While it is tempting to do a complete analysis of the research, in this post I will point out a few issues with it, both from a technical perspective and an ethical one. In doing so I will reference and quote a few sections. However, it will not be a full analysis of all of the paper.
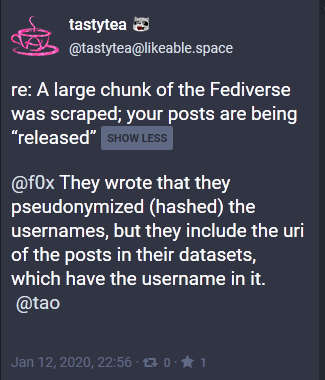
The research papers both contained datasets: the first one had focused on meta data; and this last one’s dataset was match-able with the previous one, even though it was “anonymized”. However, it was brought to my attention that their anonymization was pointless, because the username was still in the URI.
The 2nd dataset, for the latest research paper, has been removed from online access with the comment:
“Deaccessioned Reason: Legal issue or Data Usage Agreement Many entries in the datasets do not fulfill the law about personal data release since they allow identification of personal information.”
Does this mean that they did not take any of these things into account when they wrote the paper to begin with? If we look at their ethical and legal considerations we can see that they half-considered it, and I would argue missed the mark. The way most people were talking about it, it did not actually seem like they even had made any ethical nor legal considerations in their research. Reading them, I realized that they probably would’ve been better off if they had written the legal consideration first, and then have that inform the ethical consideration.
Legal and Ethical Considerations
In the legal consideration, they said that from what they had gathered they had not found anything in the ToS (Terms of Service) of the standard agreement, bundled in with a Mastodon installation, indicating that they were breaking it by doing this gathering of data. I would like to argue that there may be ethical considerations about not technically breaking any legal barriers. What do I mean when I say this? I’m trying to convey that the legal considerations could have also had ethical concerns. As the saying goes: just because you can do something doesn’t mean you should.
In the legal section they also write:
“In the terms of service and privacy policy the gathering and the usage of public available data is never explicitly mentioned, consequently our data collection seems to be complaint with the policy of the instance.”
I can understand that if a legal document does not explicitly mention something you may feel like you have free rein. Stating that there is nothing explicitly mentioned, may indicate that there’s something implicit that they chose to ignore. However, they do not elaborate. If they had followed the legal considerations up with the ethical considerations, maybe they could have discussed the ethical implications of the decision they made there.
Further, they do recognize that each instance has the ability to adopt their own Terms of Service (ToS), but then seemed to have not followed through and actually checked if any of these 300 something servers had added their own ToS. I feel like there’s a clear disregard for the possibility of there being other ToS. With no indication that they checked a certain % (say 10%) of the listed servers and their ToS, which would have showed that a clear “majority” used the standard ToS. They could have recognized what differences do exist. I feel like there was simply an assumption rather than actual research done for this part.
Did they make any ethical considerations? It seems to mostly reflect the collection methodology, rather than answering any ethical questions, such as:
- Would the users of Mastodon want to / expect to have their data scraped?
- Would it be better to ask servers/users if they would want to participate in the research?
- Is this research actually a Computer Science research, or should it be a Social studies research paper, taking into consideration such ETHICAL questions?
- Should Computer Science have mandatory ethics courses?
Credit where credit is due: The last question is lifted from several people on the fediverse who’ve asked it before this research paper was published, and continued to ask after it was published.
I think the biggest issue here, is that because these researchers do not seem to understand some of the culture on Mastodon (no there’s not only one culture, but there are some which come to mind for me) and have some basic misconceptions about the community and software, it was hard to come to any useful ethical considerations. Would they have allowed themselves to come to the conclusion that they should not publish their paper? Probably not.
Technically the Content Warning
While there are two research papers available to me, I only want to focus on the misconceptions in this research paper: “Mastodon Content Warnings: Inappropriate Contents in a Microblogging Platform”. I believe that their entire conclusion is way off because they simply misinterpreted how a feature is used on the servers.
In their methodology they described how they interpreted the technological “sensitive” field in the meta data:
“each toot provides the fields related to the inappropriate-ness of its content, namely the entries “sensitive”, “content”,“spoiler-text” and “language”. The boolean field “’sensitive” indicates whether or not the author of the toot thinks that the content is appropriate. If the toot is inappropriate, the field is set up to “True” and the field “spoiler-text” would contain a brief and publicly available description of the content.” (Sic)
Correction: The sensitive tag happens when someone adds a Content Warning to their post. The sensitive tag says nothing about the actual content, and what the person thought about it when they did us (I’ll elaborate on what Content Warnings mean culturally on Mastodon further down).
However, they had interpreted the technical function of content warnings correctly, with this first two sentences:
“By clicking on the “CW” button, a user can enter a short
summary of what the ”body” of her post contains, namely a
spoiler-text, and the full content of her toot. Automatically,
the system marks this toot as “sensitive” and only shows the
spoiler-text in all the timelines. (…)
The next part was unfortunately where one of the misinterpretations of the data happened:
“(…) We exploit this latter feature
to build our released dataset. This way the toots are labelled
by the users, and we assume that they are aware of the policy
of the instance and aware of what is appropriate or not for
their community.”
This section emphasizes that they believe that the Content Warning is only used to mark content as sensitive if it’s inappropriate, and if it does not belong on the server. Correction: If the content does not belong on the server, the users is most likely going to be banned.
This point was an reiteration of the previous statement in the methodology:
“Here we describe the collection methodology of the two main elements of our dataset: i) the instance meta-data and ii) the local timelines of all the instances which allow toots written in English.
…
Specifically, we are interested in the full description of each instance and the list of allowed topics. From our viewpoint, these two fields contain the information related to the context which makes a post inappropriate or not.”
The misinterpretations seem to be stemming from assumptions, rather than research, about how the technology is used, what the “sensitive” tag actually means, and how it’s used on the over 300 servers used. This leads me to the cultural and social misinterpretation.
The Social Construct of the Content Warning
I believe that the biggest issue is that this research was in computer science, without any social science involved, with no consideration to the social part of social media. I’ve already noted that their assumption and interpretation is incorrect, so how are the Content Warnings used?
While I only have the empirical evidence from the servers I’m connected with, I’m still going to go out and say that: Content Warnings are in fact not used for content we do not believe belong in our communities.
Rather, Content Warnings can be used in many ways. One way to describe it is simply as a subject line, similar to email. In some cases we will talk about more sensitive subjects, like addictions, drugs, war, news, politics. This is not to hide the content, but rather to offer the people reading it a chance to decide if they want to open it or not. If today is a day where reading about US Politics would just drain all my energy, I can choose to not open it.
We can also use it for other things, that may be slightly sensitive to some, like food, meat, sex, nudity, private, venting (of emotions). It’s also common to use for post about money, house-hunting, mental and physical health, very positive emotions and very negative emotions. In some cases it offers us a chance to unburden ourselves, without dumping those emotions onto someone who is not given a fair chance to prepare themselves for it.
There are other fantastic uses for Content Warnings, one which is especially dear to the community’s heart is as a setup for a joke. Some times the same CW will circulate in a meme like fashion, and contain things that make us giggle. Another common one is as spoiler warnings for Movies or TV series, or even books or other readings. You can then use the headline to tell everyone which TV series you’re about to talk about, and also denote which episode. This was great towards the last year of Game of Thrones for example, when a lot of people would be talking about it the day of the new episode.
So, to emphasize, we do not post Content Warnings because we believe the subject is inappropriate, we just want to offer the reader of the post the chance to give informed consent. And using informed consent, is something which I believe the authors of the research could take a lesson from.
This article was supported by my patrons. If you enjoyed it and would like me to be able to write more of them, feel free to head over to my patreon page and pledge your support!
Alternatively, check out my support page for more info.